03-01: Lexical Analysis Part 1
Token Class (or Class)
- In English: noun, verb, adjective, …
- In a programming language: identifier, keywords, <, >, numbers, …
- Token classes corresponds to sets of strings.
The goals of lexical analysis
- Classify program substrings according to role (token class):
- Token is a pair
<token class, substrings>.
- Communicate tokens to the parser.
03-01: Lexical Analysis Part 2
- An implementation must do two things:
- Recognize substring corresponding to tokens (lexemes);
- Identify the token class of each lexeme.
03-03: Regular Languages Part 1
- Regular Expressions:
- Single character;
- Epsilon (ε);
- Union (A+B);
- Concatenation (AB);
- Iteration ().
- The regular expression over Σ is the smallest set of expressions including:
-
-
-
-
-
-
03-03: Regular Languages Part 2
- Regular expressions specify regular languages (set of strings);
- Five constructs:
- Two base cases (empty and 1-character strings);
- Three compound expressions (union, concatenation, iteration).
- Let Σ be a set of characters (an alphabet). A language over Σ is a set of strings of characters drawn from Σ.
- Meaning function L maps syntax to semantics. For regular expressions:
.
- Meaning function:
- makes clear what is syntax, what is semantics;
- allows us to consider notation as a separate issue;
- because expressions and meanings are not 1-1.
04-01: Lexical Specification
Algorithm:
- Write a regexp for the lexemes of each token class;
- Construct , matching all lexemes for all tokens;
- Let input be . For check ;
- if success, then we know that for some ;
- Remove from input and go to 3.
Extensions:
- Maximal munch;
- Choose the one listed first;
- Create rule for error strings.
04-02: Finite Automata Part 1
- A finite automation consists of:
- An input alphabet Σ;
- A finite set of states S;
- A start state n;
- A set of accepting states F ⊆ S;
- A set of transitions .
04-02: Finite Automata Part 2
DFA:
- One transition per input per state;
- No ε-moves.
NFA:
- Can have multiple transitions for one input in a given state;
- Can have ε-moves.
Difference:
- A DFA takes only one path through the state graph;
- An NFA can choose;
- An NFA accepts if some choices lead to an accepting state;
- DFAs are faster to execute;
- NFAs are, in general, smaller (exponentially).
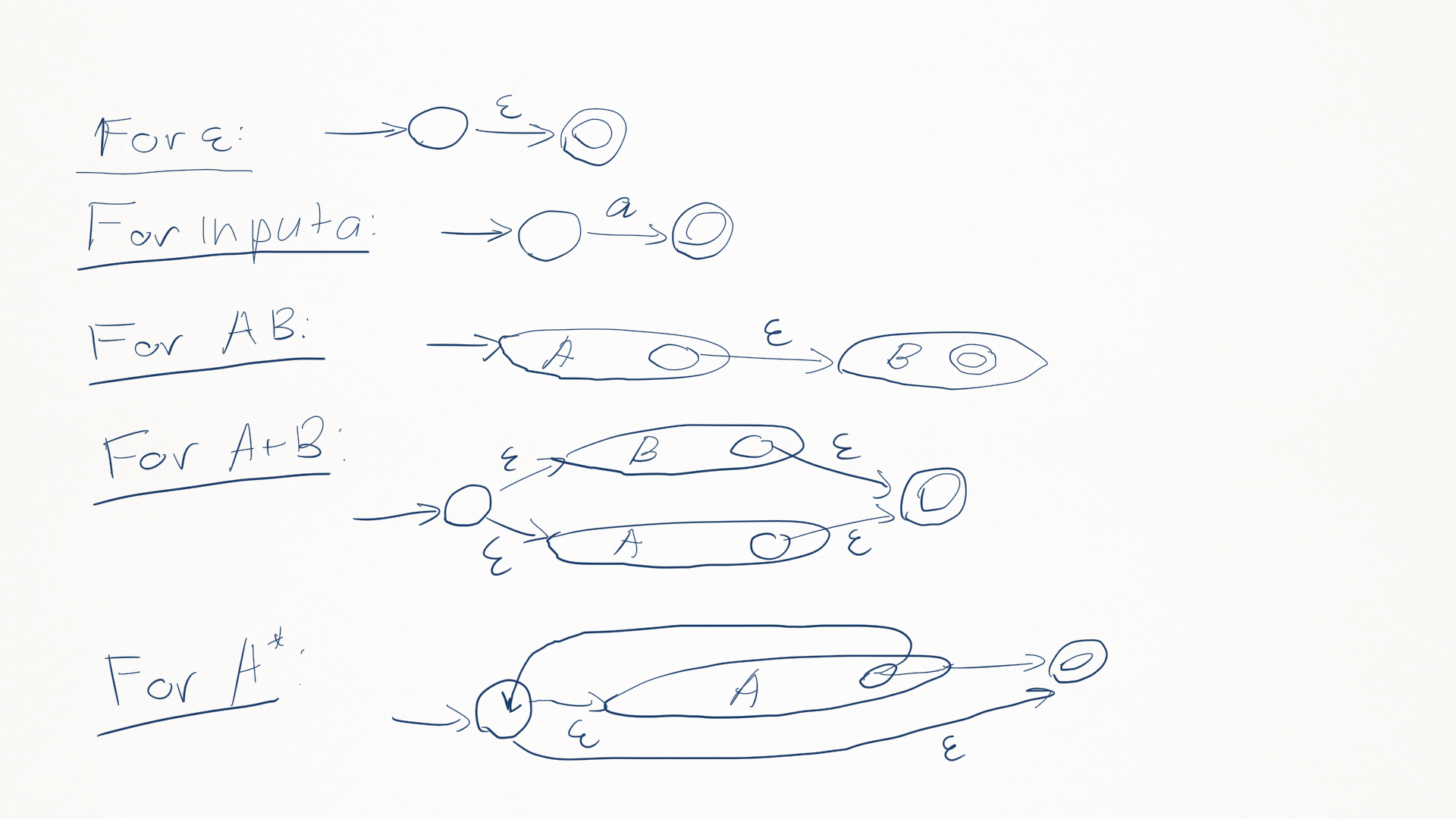
04-03: Regular Expressions into NFAs
- Algorithm:
- Lexical Specification
- Regular Expression
- NFA
- DFA
- Table-driven implementation of DFA.
- For each kind of regexp, define an equivalent NFA:
04-04: NFA to DFA
- ε-closure of a state is all states that are reachable by ε-edge from a state.
- DFA:
- states: subsets of S except the empty state, S - set of states of NFA;
- start: ε-closure(s), s - the start state of NFA;
- final: { , F - final states of NFA };
- trans: if .
04-05: Implementing Finite Automata
- A DFA can be implemented by a 2D table T:
- One dimension is states;
- Other dimension is input symbol;
- For every transition define .